
How do I evaluate LLM coding agents? 🧑💻
...aka when can I hire an AI software engineer?


In previous posts, we tracked the evolution of LLM Agents and strategies for evaluating them. One of the areas that shows the most promise for LLM Agents in the short to medium term is software development. Many projects and companies are using LLMs to build Agents that can work specifically for software development applications including code generation, optimization, enhancing security, explaining code, documentation etc. at a variety of touch-points in the dev process (e.g. IDE, terminal, issue tracker). Despite that, evaluation of coding agents is still a nascent area. Here we look at the current state of the field.
AI Coding Assistants and Agents
The capabilities of coding agents built using LLMs have evolved from autocompleting a few chunks of code to generating code to complete a Pull Request (PR) or even creating entire repositories (repos). This progress has been enabled by the underlying LLM apps evolving through the following stages:
Single LLM calls
Clever prompt engineering
Connecting to tools and code repos to get richer context
Role playing
Task decomposition and execution
GitHub Copilot was the first agent to gain large scale adoption via its integration in Visual Studio Code (VS Code) to help with autocompleting code snippets. It was initially released as a tech preview in June 2021, using OpenAI Codex a modified version of GPT-3.1 Other assistants that are currently on the market with similar features include Tabnine, CodeWhisperer (Amazon), Cody (Sourcegraph), Ghostwriter (Replit), and Cursor. The advanced version of CoPilot called CoPilot X includes personalized documentation generation, automated PR descriptions and testing, and CLI help. OpenAI’s Code Interpreter built into ChatGPT is an attempt to bring the programming language runtime inside the chat environment (vs. the other approaches of integrating the LLM into the IDE).
In parallel with the above products improving their accuracy of autocomplete, there have been several open source and academic projects in the past few months that have demoed the idea of writing several lines of code across files to automatically fulfill a PR or even generate an entire repo from scratch. Examples of projects for generating entire codebases include gpt-engineer (42k stars) and smol-dev (10k stars). MetaGPT, Self-collaboration, and CAMEL are approaches that set up a team of agents with different roles such as developers, debuggers and product managers in order to complete the overall project. Each agent in the team is instantiated with a different system prompt to the LLM, and invoked at defined times in the overall sequence.

Benchmarks
The most common evaluation benchmarks used today were created to measure the accuracy of the base LLMs on coding tasks. These are:
HumanEval - Hand-written code evaluation dataset developed by OpenAI consisting of 164 programming problems with several unit tests per problem. Care was taken to avoid overlap with Github to avoid contamination from training data used for GPT-3 or Codex.

Example of task in HumanEval, and completions generated by Codex MBPP - Mostly Basic Python Problems Dataset from Google Research consisting of 974 programming tasks designed to be solvable by entry-level programmers along with 3 unit tests each. Example task: “Write a python function to remove first and last occurrence of a given character from the string."
MultiPL-E or Multilingual Human Eval - Translations of HumanEval from Python to 18 programming languages via mini-compilers: C++, C#, D, Go, Java, Julia, JavaScript, Lua, PHP, Perl, R, Ruby, Racket, Rust, Scala, Bash, Swift and TypeScript.

Below is a leaderboard of accuracy of closed and open source LLMs on these benchmarks (as of August 24, 2023):
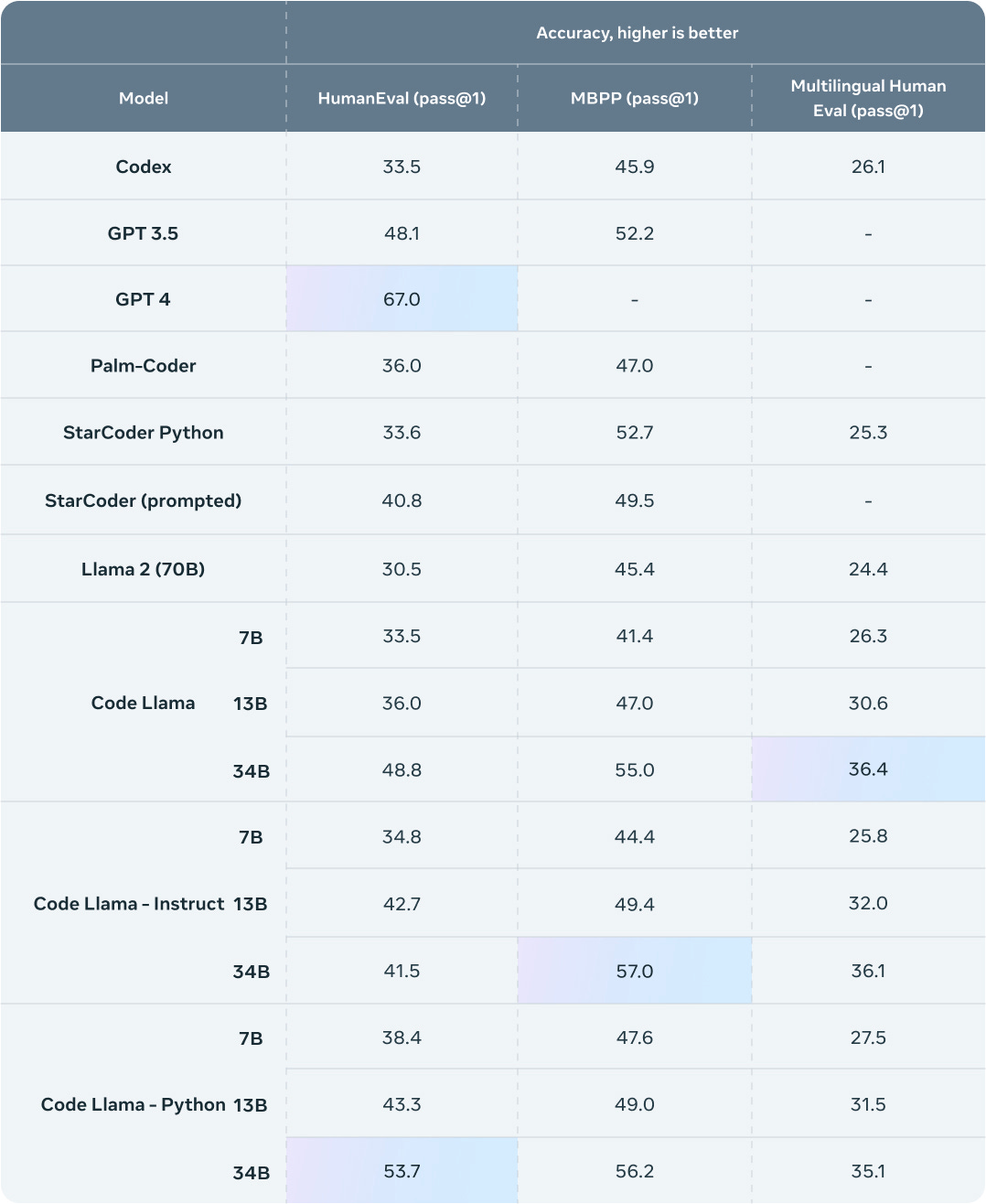
While GPT4 is still in the lead, the recently released Code Llama open source model ranks ahead of GPT3.5.
Meta-GPT and Self-collaboration have built role-playing agent frameworks on top of base LLMs and shown improvements over the base model accuracy results reported above.

MetaGPT is able to drive significant improvements in the pass rates on both MBPP and HumanEval (from 67% on GPT-4 to 81.7% on HumanEval, and from 67.7% on Codex+CodeT to 82.3% on MBPP).

Self-collaboration gets to 74.4% on HumanEval and 68.2% on MBPP.
More general agents
Exciting attempts are ongoing to create more general agents that can solve a wider range of tasks that include but go beyond coding. As mentioned in our previous post on the evolution of agents, LLMs can act as task planners and use connections to APIs, tools and databases to execute those tasks. (Auto-GPT is an example of such a framework and for a detailed review check out Lilian Weng’s post.) Our qualitative observation has been that with the current state of LLMs the more general one tries to make an agent the less reliable is its performance. We’ve seen a couple of relatively new benchmarks attempt to standardize the quantitative measurement of general agent performance on the path to tracking and improving their reliability.
AgentBench - A fairly comprehensive suite of 8 environments across coding, OS cli, general knowledge, games, and browsing automation

AgentBench: Source: https://arxiv.org/abs/2308.03688 AgentBench focusses on the use of LLMs directly as Agents without any additional role-play or frameworks for planning and execution. In their benchmark, the authors tested 25 LLMs.

AgentBench: current rankings of LLMs. Source: https://arxiv.org/abs/2308.03688 The closed source models are ahead of the open source LLMs in the current rankings.
Auto-GPT Benchmarks - Focuses on Agent framework benchmarking. Developed by the team behind AutoGPT. Currently Beebot is in the lead and Auto-GPT ranks #3. They cover tasks such as coding, information retrieval, and safety.


Fine-tuning
With the releases of Star Coder, Llama 2, CodeLlama and the GPT3.5 fine-tuning API there are now several options available for users to fine-tune models on their own code bases and specific tasks. SQL Coder is a NLP2SQL (or text to SQL) model that outperforms GPT3.5, and with fine-tuning on individual schema it can exceed the accuracy of GPT4. SQL Coder has 15B parameters and used Star Coder as the base model. Number Station announced NSQL Llama 7B which can match GPT4 performance for NLP2SQL. They used Llama 2 as the base model.

Gorilla is an approach to solving tasks defined in natural language by selecting from among 1600+ API calls (NLP2API) by fine-tuning a base Llama model. They report higher accuracy compared to GPT-4.

Challenges
We’ve seen that while there are emerging benchmarks for coding agents, it is still a nascent field, and end users need to think carefully about evaluations. At this stage most users will likely need to set up custom evals that are task specific for their use case. Tools such as Log10, let you perform the necessary steps for custom evaluations and fine-tuning:
Curate and bootstrap your logged data
Set up the datasets for custom evaluations and fine-tuning
Perform the underlying compute for evaluations and fine-tuning
How are you looking to measure your coding agents? Write to me and let me know.