
Evolution of LLM Agents
...and how to avert a crisis on further progress!


While OpenAI’s GPT-3 API has been live since mid-2020, programmatic use of large language models (LLMs) has been rapidly evolving over the past year from single API calls to increasingly complex formats that enable LLMs to act as agents and fulfill more complex tasks. This post traces the evolution of these agentic capabilities in LLMs and discusses the opportunities and challenges ahead.
The vision for this rapidly advancing area is that of agents with increasingly complex task completion ability with access to Internet scale data and tools. Every individual could have access to extremely powerful tools in the form of these agents and the potential for increase in productivity is enormous as already seen by reported productivity gains ranging from 30% to 200% in areas such as coding, marketing, sales, legal, financial advice and customer support. Extrapolating out this trend, one could foresee that many functions of a corporation could get significantly augmented if not fully automated. Individual consumers could also leverage AI agents as proxies to help them with their daily lives by researching large volumes of text, comparing options, and simplifying complex decisions.
Here’s a summary of where we are so far.

Next, let’s go through each of these levels of Agent abilities briefly.

Level 1 (mid-2020-): In the first wave of single LLM API call usage, we saw applications such as copywriting proliferate (e.g. Jasper, copy.ai). These helped save marketing and sales professional countless hours with writing blogs and emails. However, there were several limitations with the use of LLMs in this way when it came to reasoning abilities, and with writing about current events or proprietary data. There were impressive gains in the accuracy and usability of LLMs even within this phase. Prior to the Instruct-GPT models (i.e., with davinci-001) one had to carefully collect and embed several examples into the prompt to get them to generate the correct output. Following the Instruct-GPT models (davinci-002 and davinci-003) one could merely state the task and get reasonable outputs from the model (although for more complex tasks having examples still helps).
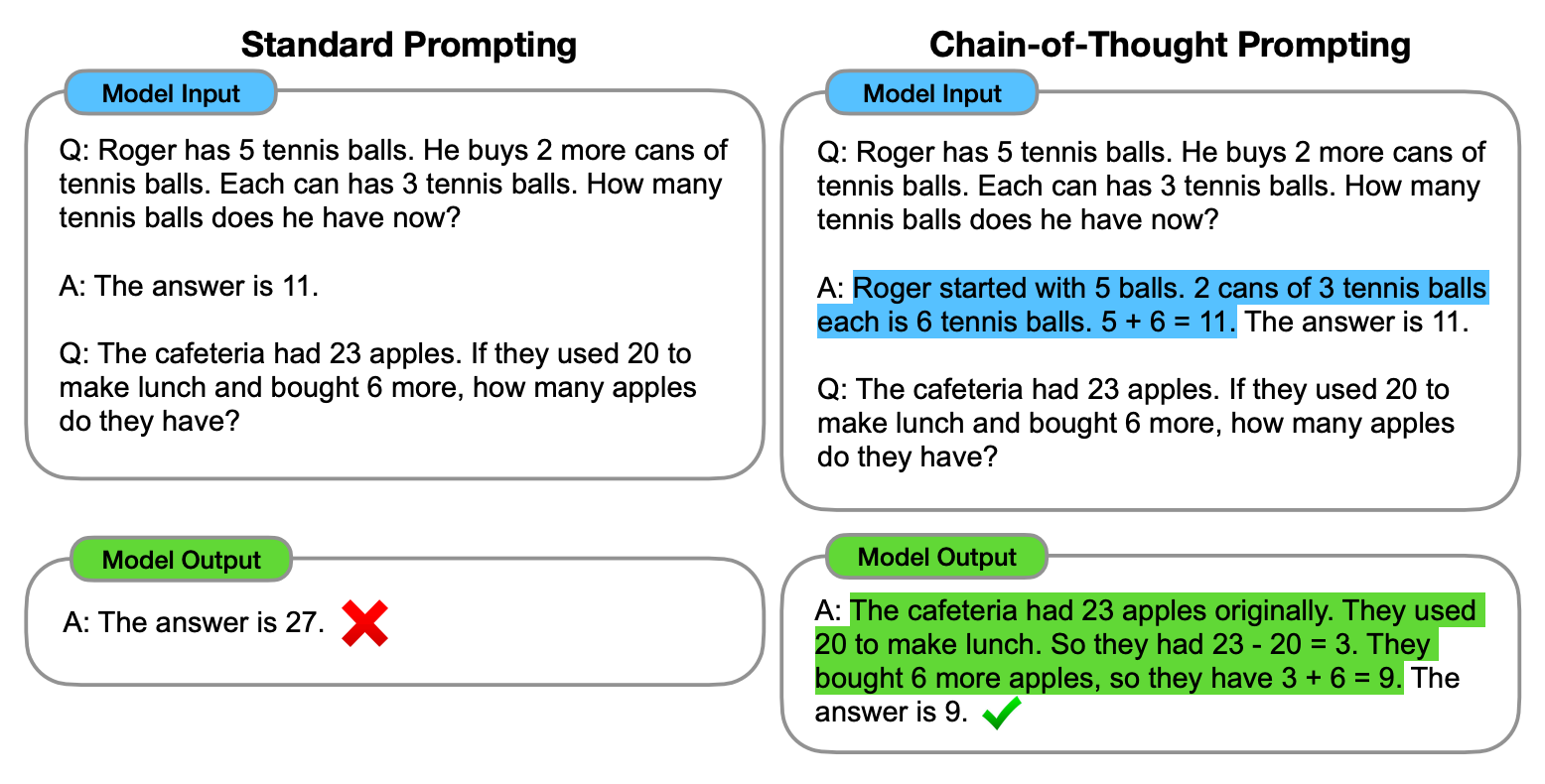
Level 2 (early 2022): In the second wave around the first half of 2022, we saw the idea of chain of thought reasoning gain popularity. This is a form of prompt engineering where instead of stating the answer directly in the prompt, one explains the step by step reasoning to the LLM. This approach led to remarkable empirical gains on a range of mathematical, commonsense and symbolic reasoning tasks.
Level 3 (late 2022): In the third wave beginning around the second half of 2022, we saw algorithmic and prompt engineered frameworks to extend LLM capabilities even further by using tools such as search engines, calculators, APIs and databases. Algorithmic frameworks such as ReAct and Self-Ask gained popularity. These ideas were incorporated into software frameworks such as Langchain and LlamaIndex and significantly lowered the barrier to adoption of LLMs by a wider audience of developers and hobbyists. Chatbot applications such as semantic question-answering over documents which might have previously taken 1000s of lines of code and weeks of development time, could now be built and deployed in 10s of lines of code and within a couple of hours.

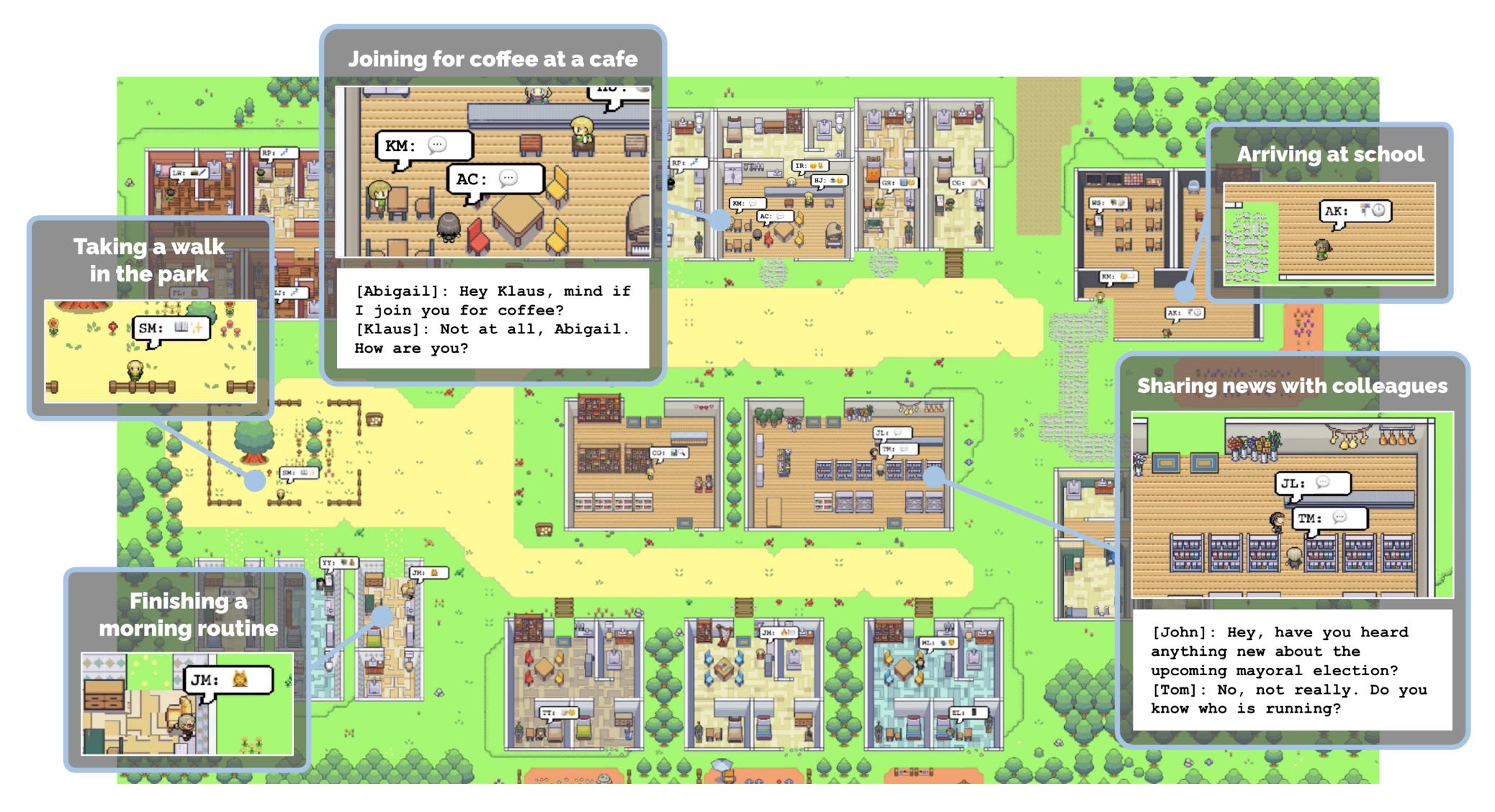
Level 4 (early 2023): In the first half of 2023, we’ve seen a fourth and fifth wave of agentic LLM capabilities gain momentum almost in parallel leveraging the advanced capabilities of models such as GPT-3.5 and GPT4. One thread has been exploring the ability of LLMs to take on multiple roles. CAMEL agents is an approach to solving complex tasks without needing back and forth interaction with a human user, and instead having the LLM take on the role of the human user in addition to the assistant role. This saves the human user from having to expend time engineering prompts or conversing with the LLM to get their desired output. The authors of Camel have found that people prefer the output of the Camel agent 70% of the time over that of a single LLM call. Examples of tasks that Camel agents can be used for include optimizing code, generating better emails or translating blogs, and even performing performing molecular dynamic simulations. Researchers at Stanford have explored the role-playing capabilities of LLMs even further with the simulation of an entire AI generated society with several LLM powered agents interacting with each other within a game environment. Although still in an academic state, simulations like these could be used to simulate out reactions to new product launches or to new laws and policies.
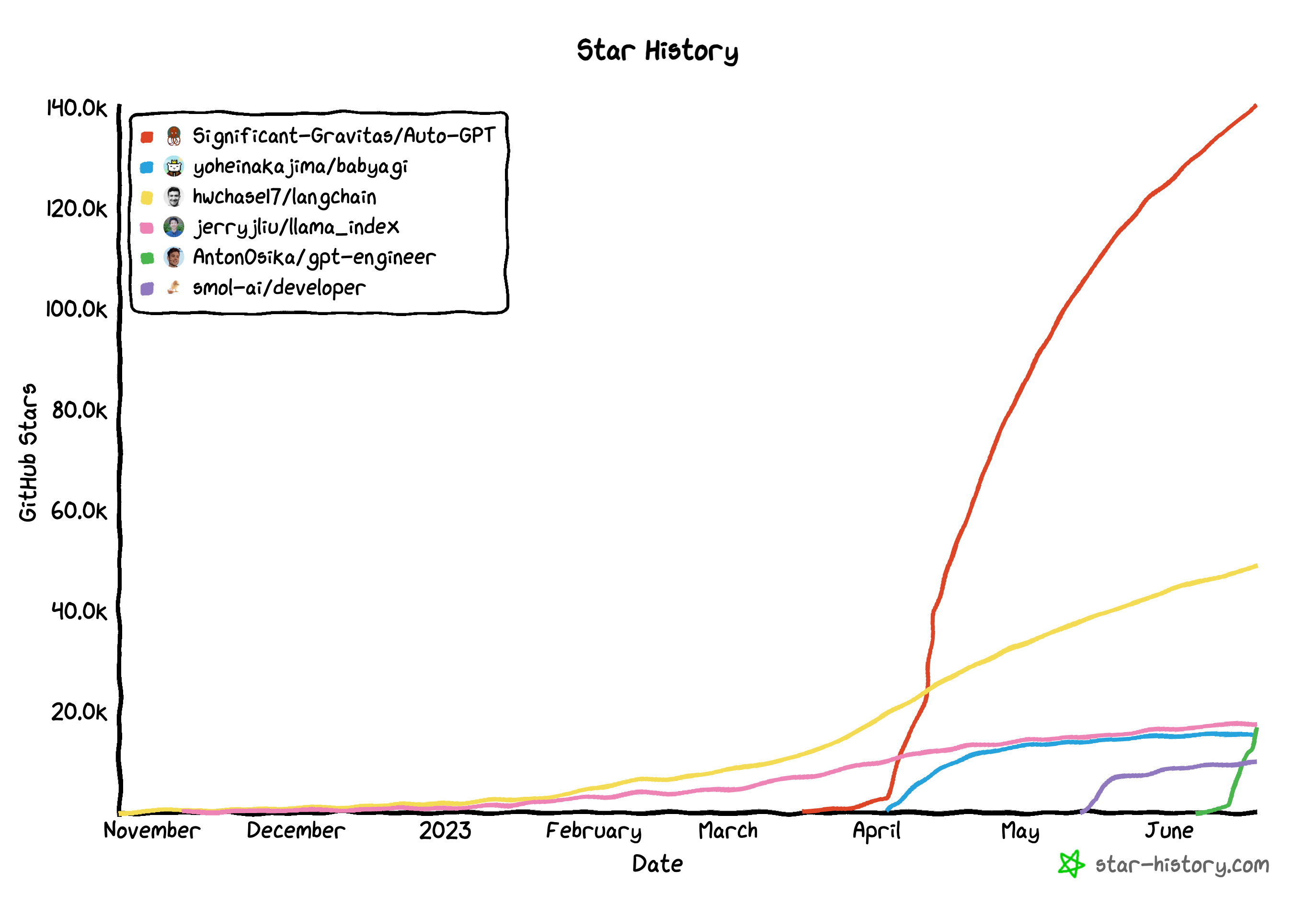
Level 5 (Q2’2023): Another thread that the community has started exploring is the idea of using the LLM to decompose complex tasks into subtasks and execute them. Demos on twitter have captured the imagination of tinkerers everywhere and make the dream of artificial general intelligence appear within reach. Natbot was an early attempt in this direction last Fall with GPT performing a sequence of actions in a browser to solve a task. Excitement (as measured by github stars and investor interest) has really taken off since April when Auto-GPT and BabyAGI were released. These leveraged the advanced capabilities of GPT4 to enable longer, more autonomous runs of LLM powered agents. Examples tasks these can be used for include doing web research on specialized domains such as cancer research or creating a business plan for a startup.
So can we then just sit back, relax, and wait for our utopian AGI powered future to arrive shortly?
As it turns out, even as each subsequent wave has demonstrated the growing agentic capabilities of LLMs, the impediments to using agents in products also keep growing. I wrote about the cost, reliability and accuracy challenges with using agents (up to level 3) in my previous post.

With level 4 and 5 Agents, here are some additional issues to consider and watch out for:
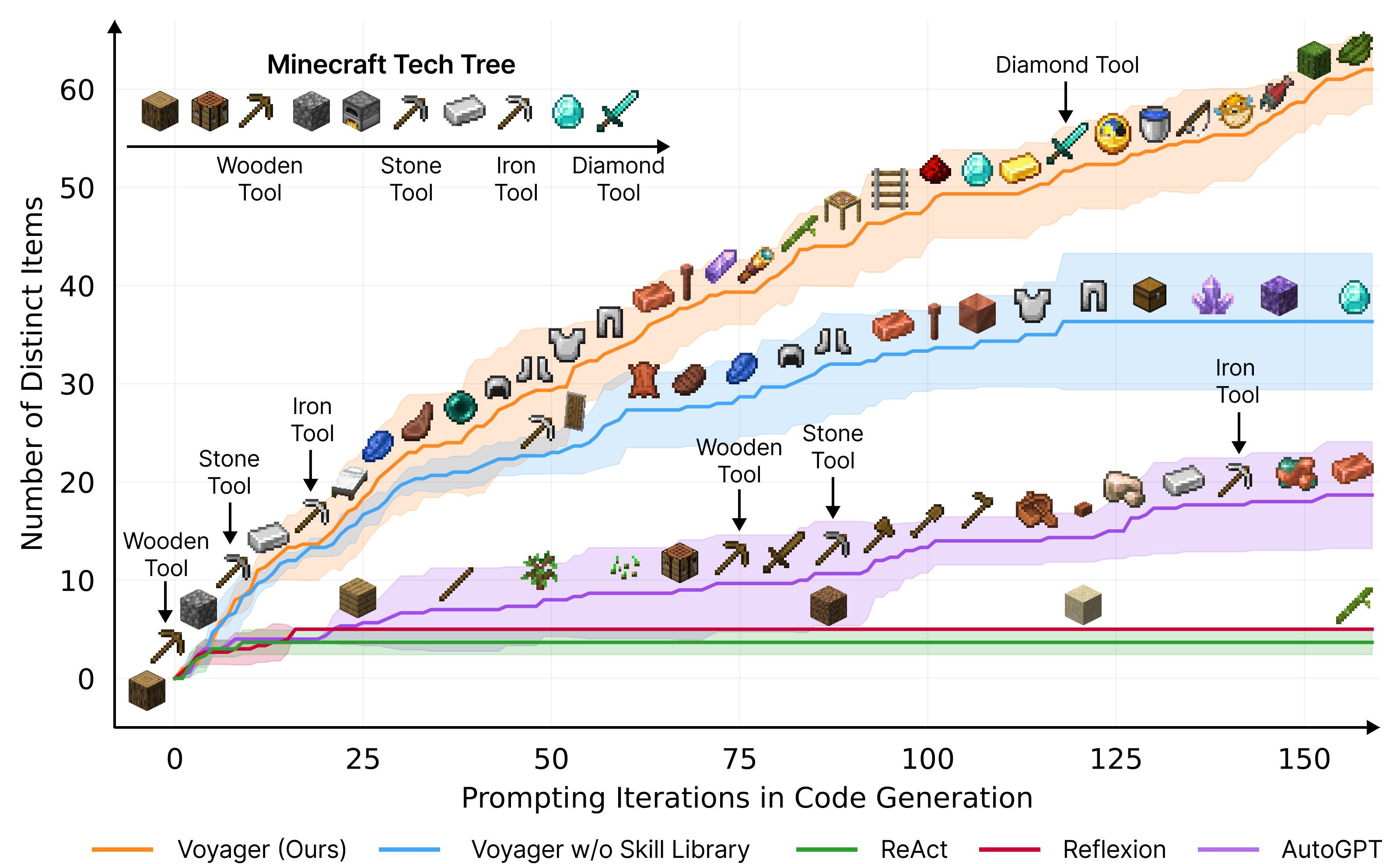
Getting stuck in loops: AutoGPT style agents can get stuck in repetitive or dead-end loops. Beyond logging and monitoring, an interesting way to overcome this algorithmically is to have the agents build and reuse abstractions rather than call the LLM each time or rely on a large vector store of history for context. Voyager is a recent implementation of this approach in the context of agents that can learn to play Minecraft better than ReAct and AutoGPT.
Latency (and cost): Many agentic uses are not making into production due to the time and costs associated with repeated LLM API calls. Although not strictly a dealbreaker for more complex tasks which would take a person on the order of minutes or hours to complete, but still something to monitor as the LLM API token use, latency and costs can rapidly pile up. One approach to reducing latency and costs could be to build and orchestrate smaller, specialized models (leveraging open source models) along the lines of the HuggingGPT paper. A side benefit of this approach could be more reliable SLAs which has been an ongoing issue in LLM application development.
Reliability: When chaining the output of LLM calls along with using tools and databases, a major point of failure can be the format or schema that goes in and out of the LLM or API calls. Guardrails and NeMo Guardrails are a couple of projects aiming to provide more input-output reliability. Recently, OpenAI introduced the concept of Functions to provide a similar functionality baked into their APIs. However, these approaches are still not completely reliable. Anecdotally, another major issue in several applications is that the same input does not always give the same output even when the model temperature is set to 0.
Evaluation: Often, there are no easy ways to measure if an Agent is getting better or worse with better algorithms, prompts, data or base LLMs. Although there are comprehensive suites such as HELM and BigBench to measure the base LLM accuracy, these are not quite correlated with the LLM application level use cases and have to be adapted. Model based evaluations are not as straight forward as the community had initially hoped. Monitoring for model hallucinations, quality and harmful content remain open issues. Evaluation will be explored in detail in the next post. Subscribe to stay tuned!
If you’re building in this space, we’d love to hear from you. At Log10 we’re building a platform to help people build, deploy and monitor more reliable LLM powered agents.

 | A guest post by
|