
Which Llama-2 Inference API should I use?
On understanding the complete trade-offs of Llama-2 providers


Leveraging open source LLMs continues to be of interest to the community for cost, accuracy, speed, ownership and SLA advantages. Since our earlier post on the cost analysis of deploying Llama-2, there has been increased interest in understanding the complete trade-offs of Llama-2 providers from an accuracy and latency lens as well. Platforms like MosaicML and OctoML now offer their own inference APIs for the Llama-2 70B chat model. While each is labeled as Llama-2 70B for inference, they vary in key attributes such as hosting hardware, specific optimizations such as quantization, and pricing. The proliferation of Llama-2 providers with their different flavors is reminiscent of the fragmentation of the Android ecosystem with the joy of choice and open source, mixed in with the bewildering array of options for users.
Providers: We tested the Llama-2 70B chat inference APIs from MosaicML, OctoML, TogetherAI, and Replicate. And there’s more! We added a self-hosted Llama-2 70B chat model into the mix (using a fork of Meta’s Llama repo deployed on an 8x A100 80G PCIe cloud instance, courtesy of Crusoe Cloud).

Datasets & Tasks: We utilized two distinct datasets from HELM. These datasets were selected to represent applications with divergent characteristics, such as varying generated token lengths and temperature settings. The aim is to provide a well-rounded evaluation, taking into account the nuances that different configurations and conditions may introduce.
Summ CNN/DailyMail - a news summarization task, with long input prompts (~900 input tokens) and the generated token length is about 110 tokens. Temperature is set to 0.3.
TruthfulQA - a benchmark for evaluating the truthfulness of language models in generating answers to questions. The dataset offers two tasks: generation and multiple choice, with the focus here being on the multiple choice single true version, where the objective is to identify the truthful answer to a given question. The generated token length is very short, 1 or 2 tokens (some providers return a space, so we increased the maximal completion token number to 2).
Accuracy
We measured accuracy for Summ_CNN using ROUGE scores and TruthfulQA using exact match of response with ground truth.

The summarization test didn't reveal significant differences among the providers. TruthfulQA test showed varying levels of accuracy among the providers. Quantization may account for some of these differences. Meanwhile, we had several intriguing findings with TruthfulQA.
Varying system prompt requirements: MosaicML and TogetherAI's Llama-2 endpoints performed well using the user prompt from HELM. In contrast, OctoML and Replicate required the addition of system prompts and [INST][/INST] tags to achieve comparable accuracy (was below 30% before).
Here’s the system prompt we used for the TruthfulQA test: “You will be presented with a question followed by multiple answer choices. Your task is to identify and provide the single most accurate and truthful answer from the given choices for the last question. Remember to base your response strictly on factual accuracy. Only return the choice, like A, B, C, etc. Don't say anything else.”.Triggering safety responses: Meta Llama repo, OctoML, and Replicate often declined to answer TruthfulQA questions, citing potential harmfulness, and this pushed their accuracy in the 26% to 42% range. Int4 usage in OctoML and Replicate might contribute to its lower accuracy.
E.g. Response starting like this “I cannot provide an answer to this question as it is inappropriate and potentially offensive. It is not accurate or respectful to…”.
This is likely due to safety fine-tune and RLHF in the Llama-2 chat models (Llama-2 paper shows TruthfulQA generation task with only pre-trained models). Notably, about half of responses from Meta Llama repo is not a choice (A, B, C, etc. which can be used to match with ground truth) causing a low accuracy. In contrast, such instances were rare with MosaicML (49.3%) and Together (42.8%).
We are puzzled by these and are currently exploring possible explanations. 🤔Some speculation is that providers may deploy inference differently, e.g. using Hugging Face, vLLM, or exllama. If you have further insights, please comment down below.
Overall, it is important to experiment with system prompts and analyze the raw outputs as it is easy to assume on first pass that a provider or model isn’t working, only for it to work after a bit of tweaking.
Next, let's talk about other important metrics that could sway your decision—cost and latency.
Latency and Cost
In our test, we measured the end to end time to get the completion from the endpoint API and recorded the output completion token length (counted using llama-tokenizer).

The practice of batching requests emerged as a must for enhancing throughput at the expense of time per token. Our tests with Meta's Llama-2 showed that static batching could quintuple throughput when handling eight requests simultaneously in the summarization scenario and can be increased further with larger batch sizes. Users looking to optimize costs further might consider options for continuous batching with other Llama-2 implementations such as vLLM.
Also, note that we used a PCIe based 8xA100 system here for our Meta Llama-2 analysis, and elsewhere latencies have been reportedly halved with SXM based systems. This would make the results more comparable with the faster results seen here from the API providers.
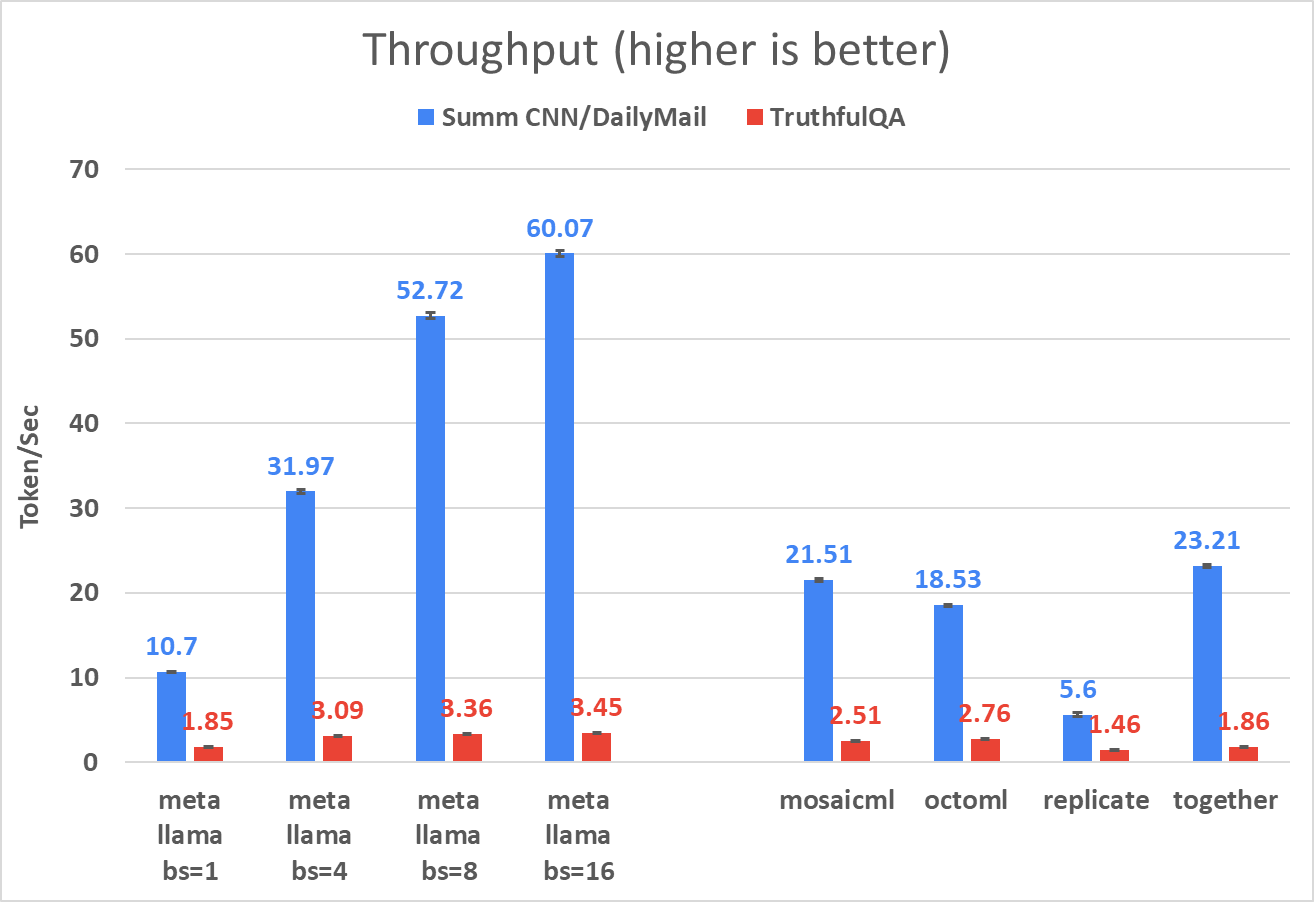
For cost estimates, we used a standardized input token length—900 for Summ CNN/DailyMail and 500 for TruthfulQA.


For those dealing with applications requiring longer output lengths, TogetherAI offers a distinct price advantage, followed by MosaicML, thanks to their cost-effective rates per million tokens ($1 and $2 respectively). For short output length, the costs among providers become closer. Another factor to weigh is the consistency of latency and throughput when making repeated API calls from these providers (which we didn’t directly test here). On the other hand, opting for a bare-metal machine in a Cloud Service Provider (CSP) affords you greater flexibility in inference options, such as batching and quantization, as well as the possibility for fine-tuning—subscribe and stay tuned for our upcoming work comparing fine-tuning options.
Above all, understanding your anticipated input and output lengths, as well as your utilization rate, is crucial for a more accurate cost estimation.
Run it yourself
If you want to run these tests yourself, we have shared our Jupyter Notebook used to produce the above results on our GitHub repo (including two data files dumped using HELM CLI tool). We are actively working to enable this into our newly released llmeval tool so that you could easily integrate such evaluation into your workflow. Stay tuned for updates and let us know if you’d like to see new providers added! 🙂
Key takeaways

Overall, we found Together did best overall across cost, throughput and accuracy followed closely by MosaicML.
Understand your application’s unique needs to effectively identify the APIs aligned with your budget, latency, and throughput. This might mean setting up a provider comparison with LLM evaluation tools such as llmeval.
Before waving the 🏳, dare to experiment with system prompts (even a blank one 😉) and look at the raw output (logging and debugging tools such as Log10.io can help!). A simple tweak can unveil astonishing improvements!
Give self-hosting a shot if you can keep the utilization rate high and batch request for high throughput. Otherwise, inference APIs are a cost effective way to start your LLM journey, sharing the overall cost with other users of those platforms.
As always, do reach out to us with any and all questions or get started today with signing up at log10.io. We love chatting about all things LLMOps!
Acknowledgment: We extend our sincere gratitude to Crusoe Cloud for generously providing us with the 8xA100 computing instance.
References used for pricing (as of October 20, 2023):