
Low-Budget Judge for High-End Hallucination Verdicts
… boosting LLM accuracy by >5% amidst label scarcity and budget constraints.


1. Overview
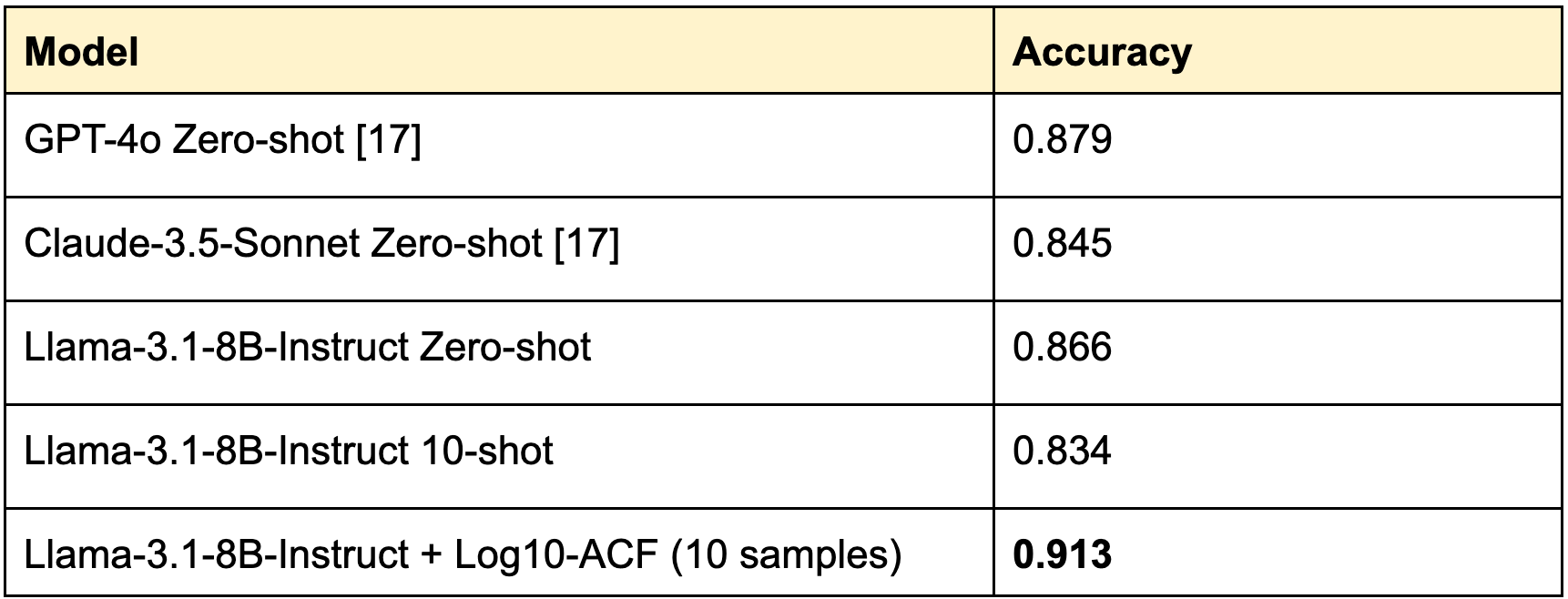
Large Language Models (LLMs) have generated lots of excitement with their emergent capabilities, finding applications in fields like education, healthcare (e.g., summarizing doctor’s notes), and even as evaluators of other LLMs in the “LLM-as-Judge” paradigm. However, accuracy and reliability—often undermined by issues like hallucinations—remain persistent challenges, even for the most advanced models. At Log10, we believe addressing these reliability concerns requires exploring diverse machine learning domains. This includes leveraging the latest insights from interpretability research and techniques from active learning (AL). In this article, we report an evaluation using the HaluEval benchmark to highlight how active learning, informed by latent space features from LLMs, can exceed the few-shot performance of the LLM-as-Judge approach. With our new acquisition function, Log10-ACF, we achieve hallucination detection accuracy that surpasses the results of our previous work on latent space readout (LSR) by 4.6 points, from an accuracy of 86.7 to 91.3. This also surpasses published benchmarks on GPT-4o (87.9), Claude-3.5 (84.5), and the latest results fine-tuning an 8B parameter model (87.3) [17].
 that significantly improves accuracy without direct fine-tuning. The 5,000 labeled set benchmark gives us a sense of performance when labeled data is surplus.")

In the next section, we provide background to active learning and discuss our active learning experiments.
2. Active Learning
LLMs generally deliver impressive few-shot results. However, their performance can be unpredictable due to high variance in accuracy. This variability, as noted in [13], poses a real challenge for applications for which consistency and reliability are critical. Efforts in active learning research seek to address this problem by ensuring efficient data sampling for supervised learning. Active learning (AL) is a strategy for efficiently building a labeled dataset for supervised learning problems by targeting and annotating the most informative samples or coreset—the subset that maintains similar statistical properties as the full data set such that models fitting this coreset also provide a good fit for the original data. In real-world active learning scenarios, prioritizing sample diversity is essential, as data often contain redundant or highly similar entries [1]. A common practice—usually referred to as warm start—is to rely on pre-existing labeled data, usually with a limited number of samples, and efficiently build more labeled datasets. In many cases, there are no pre-existing labeled samples. Hence, a process for creating this initial set to kickstart the active learning cycles is necessary. This is referred to as the cold start problem. We situate this write-up within the intersection of AL and language modeling. Hence, in the subsequent sections, among many existing related works in the active learning literature, we focus on recent works that have explored the warm start and cold start strategies within the context of LLMs.
2.1 Warm Start Strategies Leveraging LLM Latent Features
Given a pre-existing labeled dataset, most LLM-related works exploit the entropy information within the BERT model to decide potential data candidates for subsequent labeling. For example, a recent work [2] inspired by the contrastive learning principles proposed a contrastive active learning (CAL) acquisition function that focuses on identifying "contrastive examples"---data points that appear similar to the BERT model based on their encoded representations yet result in significantly different predictions. This acquisition function seeks out instances where the model's internal representation and output are at odds. The assumption is that acquiring such contrastive examples relates to acquiring difficult examples near the decision boundary of the model. The pre-trained BERT model is used as the probing model on some initially labeled samples. This model is then fine-tuned in subsequent iterations to better identify contrastive pairs.
In a more recent work, Kim and Shin [1] observed that locally sparse regions tend to have more informative samples than dense regions. Hence, they proposed a density-aware coreset (DACS) selection approach. The strategy is to estimate the density of the unlabeled samples and select diverse samples, mainly from sparse regions. An assumption is made that pre-existing labeled data exists. A classification layer is attached to an architecture of choice to extract low-dimensional features. Local subsets of points are grouped and accessed by a hashing algorithm (locality-sensitive hashing). These steps reduce the computational bottlenecks in dealing with high-dimensional data and large samples, respectively. Points are then clustered by an optimization process that seeks to minimize variance within classes and maximize the variance between classes [3]. Samples are finally selected from clusters using a k-center greedy algorithm [4]. While warm-start is a popular and the most commonly used technique, it is susceptible to potential biases that might be present in pre-existing labels and requires efforts to obtain or label a warm-up dataset.
2.2 Cold Start Methods
In contrast to warm start, no labels are available initially in the cold start setting. Data samples are selected from a completely unlabeled pool. This absence of pre-existing labeled datasets could be advantageous as it eliminates the potential biased influence of the warm-up datasets and allows for better flexibility in adapting to new or evolving tasks as it is not constrained by previous labeling decisions. As an example, ALPS (Active Learning by Processing Surprisal) [5] focused on the cold start problem, leveraging cross-entropy loss in BERT-based models to inform sampling. ALPS aims to select the samples that “surprise” a pre-trained model. It leverages the cloze-style prompt approach used in training BERT by masking 15% of tokens within each input sequence and tasking the pre-trained model to predict the missing tokens. The cross-entropy loss for the predicted tokens (against the ground truth) is used to obtain ‘surprise’ embeddings. K-MEANS clustering is done on these embeddings, and samples close to cluster centers are selected.
The idea of selective annotation given a fixed budget is also relevant in in-context learning. For example, Vote-k [6] focuses on selecting samples to be annotated for in-context learning. Vote-k is a graph-based selective annotation approach for LLM in-context learning which aims to promote diverse and representative selection by first creating a graph where the vertices are the unlabelled instances. Each vertex is connected to its k-nearest neighbors—determined by cosine similarity between embeddings. Every vertex is scored using a score function, and the vertex with the maximum score is selected at each iteration. Vertices are updated such that the scores for vertices close to the selected vertices become low. This encourages distance-based diversity. We use insights from these works to inform the development of our sample acquisition functions, with applications in hallucination detection.
3. Our Approach
Our objective is to improve the detection of intrinsic hallucination, which may be inherent in a Retrieval Augmented Generation (RAG) system using LLM-as-a-Judge with a fixed annotation budget—annotation budget being the size of data can be labeled given available resources. We used the qa_samples subset of the HaluEval dataset [10] as provided in [11], which contains 10,000 questions with knowledge from Wikipedia and question text and ground-truth answers collected from HotpotQA [16]. HaluEval is a benchmark dataset for intrinsic hallucination evaluation in RAG systems. Given HaluEval data pool D, we sample n instances, such that n: 10 ≤ n ≤ 40. We extract the labels for each set of n samples to obtain a train set Dt. Our test set becomes D \ Dt (i.e., D excluding Dt).
In customer applications, data with labels are absent at the outset, making this a cold start problem. Inspired by the works discussed above, we approach the cold start problem by leveraging information within the LLMs’ latent space. We fit a linear probe (logistic classifier) on the activations from the last layer corresponding to the last token of the sequence. Two types of coreset sampling baselines were explored for each category (i) Random; where a fixed number of samples are selected randomly from the data pool for labeling (ii) Clustering+Random; where we apply dimensionality reduction using uniform manifold approximations and projection (UMAP) [8] on the activations and then perform hierarchical density-based clustering (HDBSCAN) [9]. Compared to using autoencoders or other deep learning approaches (which requires training and tuning), UMAP requires far fewer configurations and, on a high level, works by creating a graph representation of the data and then optimizing a low-dimensional graph to be as structurally similar as possible. Regarding clustering, the hierarchical density-based approach guarantees better clustering results, especially when there are non-linear and non-spherical structures within the data. We then uniformly sample a certain number of points from n dominant clusters (clusters are sorted by size in descending order) to make a train set for annotation. See Figure 3 for comparison.
We observed a few things: (i) that with only 10 labeled samples from HaluEval dataset, linear probes outperform state-of-the-art zero-shot (mean of 86.6%) and few-shot (mean of 83.4%) evaluation of models in the same class as Llama3.1-8B-Instruct for hallucination detection with only a handful of labeled samples (ii) that although the Clustering+Random approach provides better representative results in the lower labeled data regime compared to Random, it is faced with the challenge of CPU compute-intensive hyper-parameter sweep across a sizable amount of hyper-parameters. This includes deciding a sufficient amount of clusters to query from and the amount to query from each cluster, among others. Moreover, uniformly sampling from clusters doesn’t guarantee an approximate coreset. (iii) as observed from previous works [7], Random has consistently proved to be a strong baseline. Random and Clustering+Random converge at nearly the same accuracy as the selected sample size increases.

To remedy some of these limitations with Clustering+Random, we developed another acquisition function (Log10-ACF) to automatically query an unlabeled pool of data to select a small subset of examples (or coreset) that ultimately result in models with high accuracy comparable with those with abundant labeled training data. Similar to the Clustering+Random approach, Log10-ACF applies UMAP to reduce feature dimensions and uses HDBSCAN to cluster the features, and then samples for representative features based on a computed diversity score. We conceptualize representativeness as how well a sample reflects the overall distribution of the dataset. We expressed it as a power-weighted sum of cluster diversity, distance diversity, and uncertainty diversity.
Cluster diversity: for good representation, we expect samples across multiple clusters ensuring that data from different regions of the feature space is included, reducing the risk of overfitting to one type of data.
Distance diversity: this helps to ensure spatial variety while sampling, preventing oversampling from any particular neighborhood.
Uncertainty diversity: Lastly, examples that are particularly hard for the model to predict should be queried. Since the entropy method can produce high confidence even for erroneous predictions, our acquisition function (Log10-ACF) instead estimates uncertainty by evaluating a point's confidence in belonging to its cluster. The uncertainty scores of neighboring points are propagated to the current point, allowing us to assess whether it lies in a region with high uncertainty. The underlying hypothesis is that points from such regions are inherently more challenging for classification.
Let d1, d2, and d3 represent cluster diversity, distance diversity, and uncertainty diversity, respectively.
Together, they form the diversity vector:
For a dataset with m samples, compute the diversity scores:
for all samples using:
The weights wi ∈ [0, 1] are associated with each diversity component di, and they determine the relative contribution of each diversity measure.
Retrieve the indices that sort the samples in descending order of their diversity scores and then retrieve the first n samples based on these indices:
This selected_indices is then used to retrieve corresponding samples from the dataset. See Figure 4 for a comparison of Log10-ACF with other baselines.
. The acquisition function is deterministic, so it guarantees consistency in results. The left plot shows performance when features are extracted from the token immediately preceding the <eot> tag that marks the end of the prompt. The right plot shows performance when features are extracted from the very last token in the prompt.")
In terms of application, our goal is to improve the performance of LLMs for hallucination detection for various applications, given a pool of unlabeled data and a low annotation budget. From our experiments, fitting a simple linear probe (e.g., logistic classifier) on a small set of labeled activations extracted from the last layer of Llama3.1-8B-Instruct and corresponding to the last token improves hallucination detection accuracy. This small set of labeled activations (coreset) is selected for labeling using our acquisition function, Log10-ACF.
4. Conclusion
In conclusion, our work demonstrates that combining LLM activations with linear probes and active learning can significantly improve hallucination detection accuracy. Specifically, we addressed the cold start problem—a common challenge in practical applications where labeled data is scarce or nonexistent. By leveraging Log10-ACF to sample diverse and high-uncertainty instances for initial labeling, we build on our previous latent space readout result to outperform the latest fine-tuned- and frontier models, including GPT-4o with only ten labeled samples. This improved hallucination detection accuracy not only enhances model reliability but could also deliver tangible business value by reducing annotation costs, streamlining deployment timelines, and improving user trust in LLM applications. As organizations increasingly rely on LLMs in sensitive applications, techniques like Log10-ACF offer a scalable path to balance cost-efficiency and model accuracy. Future research could explore the generalizability of these findings to other domains, such as computer vision and optimizing computational costs.
For more in-depth insights or any questions about our research, feel free to contact us at ai@log10.io. We’d love to hear from you!
Bibliography
In Defense of Core-set: A Density-aware Core-set Selection for Active Learning
Cold-start Active Learning through Self-supervised Language Modeling
Selective Annotation make Language Models Better Few-Shot Learners
DeepCore: A Comprehensive Library for Coreset Selection in Deep Learning
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
Halueval: A largescale hallucination evaluation benchmark for large language models
PRISM: A Rich Class of Parameterized Submodular Information Measures for Guided Subset Selection
Which Examples to Annotate for In-Context Learning? Towards Effective and Efficient Selection
HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering
https://huggingface.co/PatronusAI/Llama-3-Patronus-Lynx-8B-Instruct-v1.1