
LLMs Know More Than What They Say
... and how that provides winning evals



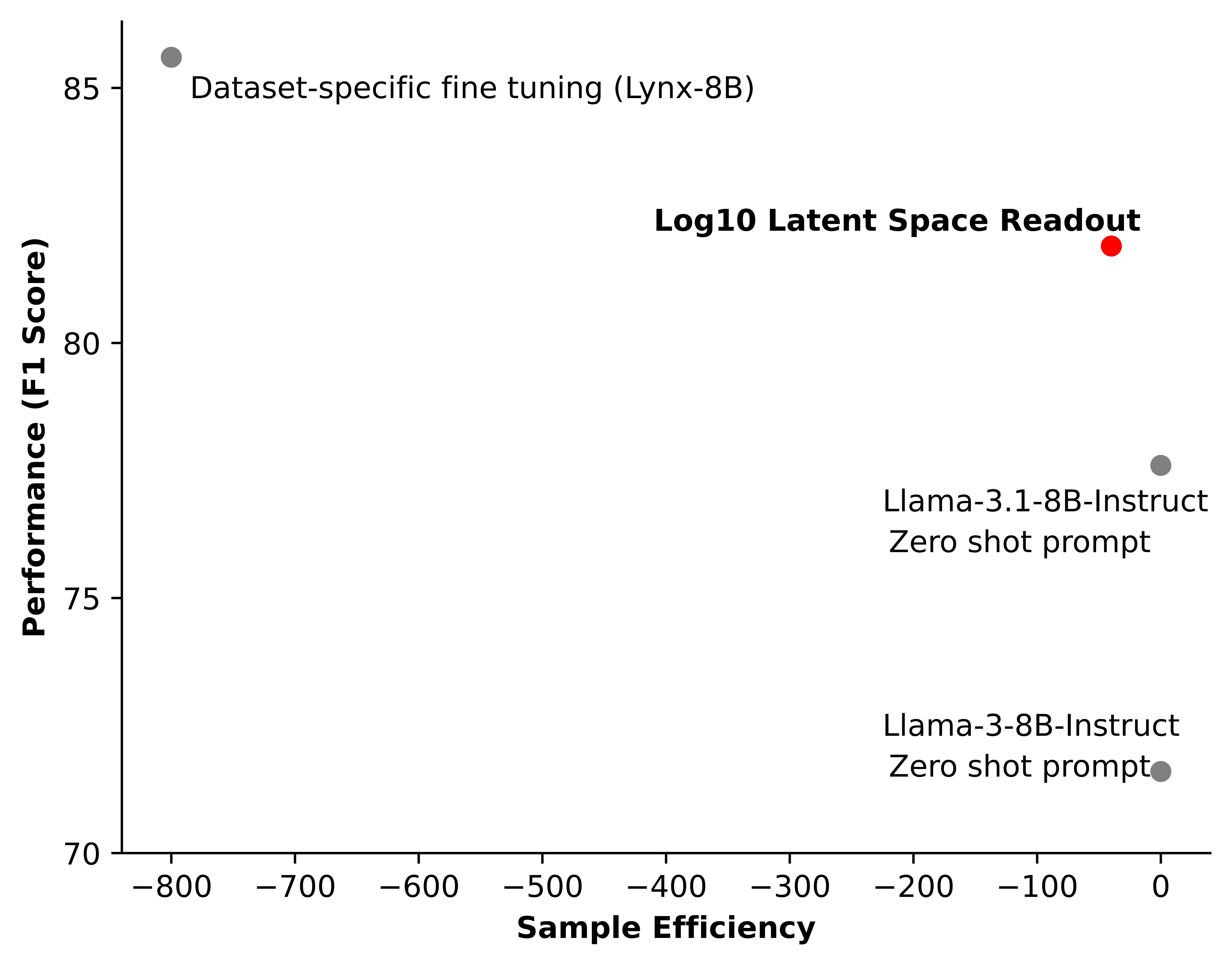
Log10 provides the best starting point for evals with an effective balance of eval accuracy and sample efficiency. Our latent space approaches boost hallucination detection accuracy with tens of examples of human feedback (bottom), and work easily with new base models, surpassing performance of fine tuned models without the need to fine tune. For domain specific applications, our approach provides a sample efficient way to improve accuracy at the beginning of app development (bottom). See “Rapidly Customizable Hallucination Detection” for details.
Good AI application evaluations separate the companies that are successful with GenAI from those that aren’t. Deploying AI apps merely based on “vibes” can cause serious financial and reputational damage. More structured approaches to evaluations also have yielded mixed results in practice – while metric-, tool- and model-based evals are fast and inexpensive, most mission critical applications still rely on slow and costly human review as the gold standard for accuracy. In this post, we share some of our research on how to improve evaluation accuracy in cost-effective and sample efficient ways, unlocking the ability to rapidly generalize to new use cases and domains.
Improving accuracy for automated, model-based evaluations has to date involved the standard set of techniques for improving accuracy of language models1. Prior to this post, additional model training has unsurprisingly resulted in the most accuracy gains, at the expense of more annotated data.
At Log10 one of our research thrusts involves applying insights from LLM interpretability research to improving model-based evaluations. In this post, we describe a novel application of latent space techniques to GenAI application evals with the following advantages:
Rapidly Customizable: 20x more sample efficient than fine tuning, with comparable accuracy
Easy to Update: Works with different base models, easily taking advantage of base model improvement without the need to fine tune again
Configurable: For hallucination detection and other binary type evaluations, easily control recall versus precision tradeoff to meet use-case requirements
Supports Numeric Scoring: Generalizes to custom numerical scoring evaluation tasks without the need for prompt engineering
Evals Inspired by Interpretability Research
This year has seen exciting developments in interpretability research [6, 8]. Research over the past few years has established the existence of semantically meaningful linear features in the transformer residual stream [1]. Linear features have been extracted via sparse autoencoders and used to steer model outputs, in both research literature and, this year, production models [6, 8]. Through these techniques, we briefly had Golden Gate Claude, a demo version of Claude that was fixated with and envisioned itself as the Golden Gate Bridge. Steering model outputs with extracted features has both been a way of showing that those features are semantically meaningful as well as a glimpse towards how better control over LLM behavior might be achieved.
Another established way of finding interpretable linear directions is via creating contrast pairs [2, 3, 10, 9]. Steering vectors are linear directions found via contrasting model inputs. These are contrasting prompts and completions, and the steering vector is computed as the difference vector in activation space. Typically best results are found via taking the mean of many pairs, for the same concept. Sometimes this method goes by the name “activation engineering”. The focus of activation engineering has been on steering the behavior of models. However, it is also possible to boost evaluation accuracy via latent space techniques, for both hallucination detection and numeric grading of custom evaluation criteria.
We apply the concept of meaningful linear directions, computed from automatically generated contrast pairs, to the task of evaluation. Our key insight is that evaluations can also be derived from projecting evaluation model activations onto meaningful linear directions. We call this approach latent space readout (LSR)2. Moreover, we find that LSR can boost evaluation accuracy over using the same LLM as a Judge in standard approaches via prompting, and even over frontier models for certain evaluation types. We show example results on open hallucination detection benchmarks and custom evaluation criteria grading below.
Rapidly Customizable Hallucination Detection
Despite the impressive capabilities of LLMs, hallucinations continue to be an issue, especially for customer facing applications or in critical domains. Recently the HaluBench benchmark [11] was proposed for RAG question answering hallucination detection. Each example in the benchmark contains a passage, a question about some context in the passage and an answer. Each example also has a label as to whether the answer contains an intrinsic hallucination, meaning the answer included information contrary to that in the context passage. The benchmark contains 6 data sources. Below we show results on a couple data sources, Halueval and PubMedQA, to illustrate the advantages of LSR.
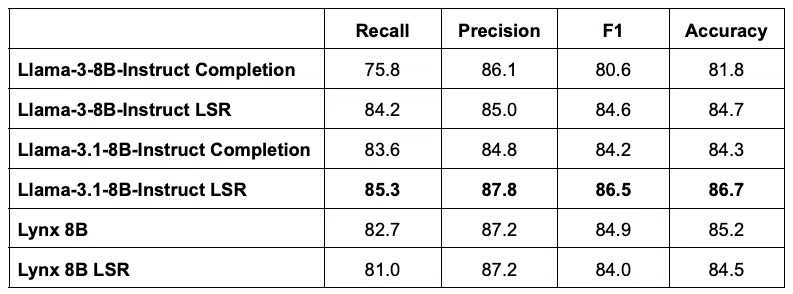
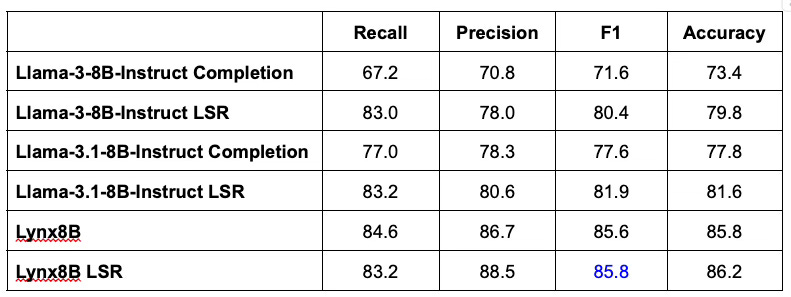
Latent space readout boosts hallucination detection accuracy, yielding results comparable to fine tuning. Consider as an example the Halueval benchmark (10,000 samples from the HaluBench benchmark). Applying LSR to Llama-3-8B-Instruct improves F1 score and accuracy over the prediction in the model completion (i.e. standard LLM-as-Judge). The F1 score is the harmonic mean of recall and precision. Recall and precision are more appropriate metrics than “accuracy” for hallucination detection performance–more on this later. Lynx [11] is a recently published model that was created by fine tuning Llama-3-Instruct on 3200 samples from HaluBench data sources, i.e. similar passage-question-answer hallucination detection examples (but not including Halueval). We see that LSR can approach the accuracy of fine tuning the same base model (84.7 vs 85.2), with comparable F1 scores of 84.6 versus 84.9.
When stronger base models are published, LSR can take advantage of the underlying base model improvement and outperform models fine tuned from previous base model versions. Llama-3.1-8B-Instruct is more accurate as a judge than its predecessor Llama-3-8B-Instruct. Applying LSR to Llama-3.1-8B-Instruct also improves F1 score and accuracy over base model prediction, and surpasses Lynx. LSR can typically be configured with as few as 30-50 examples of human feedback. Incorporating the improved base model is a lightweight process compared to fine tuning again from Llama-3.1-8B-Instruct. Applying LSR to the fine tuned model however, does not always provide a performance boost3.

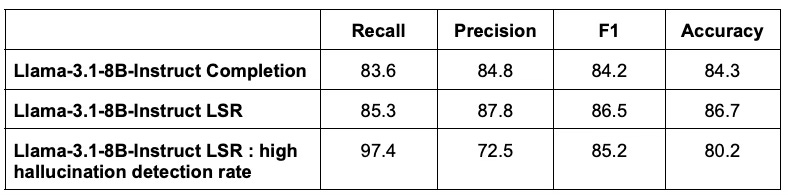
Critical applications require higher recall; accuracy is an incomplete metric. For hallucination detection, recall and precision are the relevant metrics to characterize evaluation performance. LSR provides an easily tunable knob for setting recall and precision to a configuration that’s appropriate for the application. For critical applications, a higher recall (hallucination detection rate) is desirable, even if that involves a tradeoff of lower precision (more “false alarms”), so long as the false alarm rate is tolerable. With LSR, the detection threshold can be set for a higher hallucination detection rate, such as in the last row of the table below–a knob that would otherwise have to be laboriously (and less effectively) tuned with prompt engineering. This is similar to the promise of more fine grained control in model steering.
LSR is not gated on collecting 100s-1000s of human feedback examples. LSR works when the amount of human feedback is small (~10s of examples), with performance comparable to fine tuning on the target evaluation task. Consider the PubMedQA test set within HaluBench, and the Lynx model as an example of a model fine tuned on this specific dataset. Lynx was fine tuned with 3200 samples across four different data sources, including PubMedQA (2400 train samples plus 800 validation). Without additional details, we assume the training set was equally distributed across the four sources. In the table below, we see that, as expected, fine tuning increases accuracy and F1. However, LSR with the base Llama-3-8B-Instruct model, configured using 40 samples, has comparable recall to Lynx8, with lower precision. Visualized below, this suggests a Pareto front of evaluation methods when it comes to sample efficiency and performance. For evaluations in a specialized domain, when a small number of examples have been collected (before fine tuning is feasible), a latent space approach provides an effective starting point.
Beyond Detection: Numeric Scoring
Setting up an automated evaluations suite is a multi-staged process, starting from assertions based tests [15] to model based evaluations. There are many types of model based evaluations to consider. Beyond binary pass/fail evaluations such as hallucination detection, numeric scoring of custom evaluation criteria can be useful for focusing developer attention on the worst offending examples, monitoring, and direct use in RLAIF (sidestepping the need to train a reward model on comparisons).
LLM-as-Judge4 struggles with numeric scoring. We have found that latent space approaches are able to fit human feedback on numeric scoring rubrics in a very sample efficient manner.
As an example, consider the CNN/DailyMail news summarization dataset, which contains human feedback for different summary evaluation criteria including summary coverage. We choose coverage as an example because of the subjectivity involved in what constitutes a good coverage summary, which could vary from application to application. Application or domain-specific criteria which involve this kind of subjectivity are where custom evaluation criteria fit into the overall suite of evaluations.
Using few-shot learning with Mistral-7b-v0.2-Instruct produces the result on the left, whereas LSR from a 7B model based on Mistral-7b-v0.2-Instruct model produces the result on the right. This LSR model predicting summary coverage has a correlation of 0.7 with human scores on a held out test set (shown below). Given noise in test set labels, we believe this is a fairly effective model, fit with 12 labeled samples.
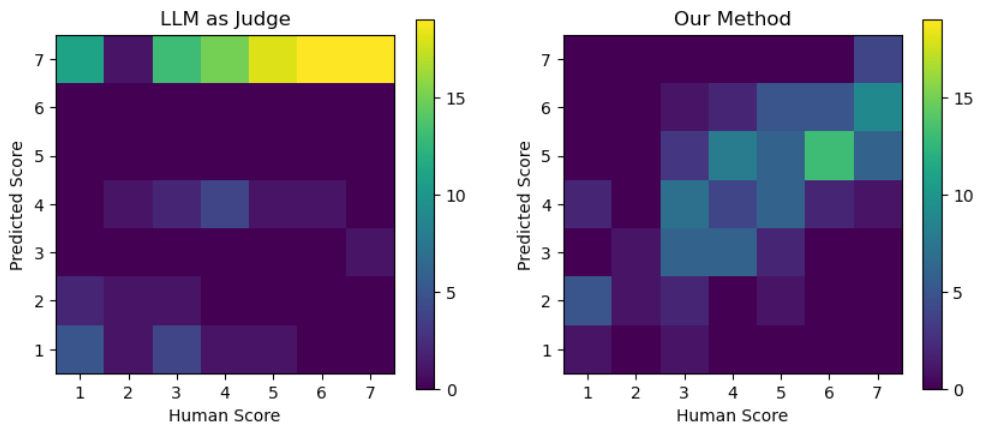
Note that for some custom evaluation criteria, we have found that it is necessary to do a small amount of fine tuning to enable accurate readouts. We do this sample efficiently using synthetic data. We observe that the lightly fine tuned model is not able to produce accurate numeric feedback (also tending to provide constant scores across a range of inputs), but LSR using the model is. We hypothesize this is because for custom evaluations, certain concepts are not represented in latent features in the base model.
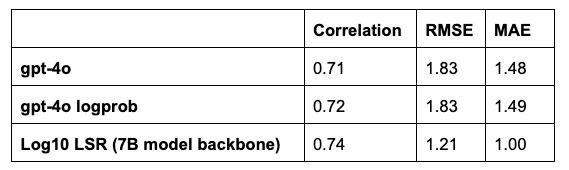
Finally, we compare LSR using a 7B parameter model with a frontier model. Below we show gpt-4o predictions from both the model completion as well as calculating an expected value score from logprobs. Our latent space method improves over both gpt-4o results, while being considerably faster and cheaper.
Your App, Your Eval
The tendency when it comes to automated evals has been to focus on models. After all, they are model-based. However, models alone, without easy-to-use and easy-to-integrate interfaces, situated as part of a system, are not solutions. Even ChatGPT, commonly thought of as a single model, likely consists of a “Compound AI” system [16] as part of the overall solution that end users interact with.
Similarly, there are many components involved in the development of a full suite of evals, starting from assertions based [15] to including model based evals. The latter should be customized to the needs of the GenAI application, whether for chatbot personality or industry-specific considerations. Log10 supports the developer throughout this journey.
Sample efficiency is key to productionizing custom evals. Log10’s platform allows you to define custom evaluation rubrics and provide subject matter expert feedback. We turn this feedback into more accurate evaluation starting with tens of feedback samples, powered by research such as what we described here. Get started with Log10 AutoFeedback today.
Log10 is investing in expanding our suite of evaluation datasets. To explore partnerships, contact: ai@log10.io
A non-comprehensive list of references
Activation Addition: Steering Language Models Without Optimization
Discovering Latent Knowledge in Language Models Without Supervision
Prometheus 2: An Open Source Language Model Specialized in Evaluating Other Language Models
https://blog.langchain.dev/aligning-llm-as-a-judge-with-human-preferences/
Model based evaluations have typically been based on language models, whether LLM-as-Judge prompting of frontier models or fine tuned smaller open LLMs [11], or fine tuning of small language models (encoder-only transformer models, e.g. DeBERTa models) [12]. The approaches to improving evaluation accuracy have involved the standard approaches for improving accuracy of language models—fine tuning [11, 12], continuous pre-training, and few-shot examples for LLMs [14]. For brevity we cite industry examples, but of course the research literature includes many examples as well, e.g. [13].
Projections onto semantically meaningful linear directions have been used for analysis of base model behavior [9] and safety of base models [4]. However, to our knowledge this is the first application of latent space techniques to an evaluation model, productionized for use in application-specific evals.
We find that a latent space approach on top of some fine tuned models may not improve performance, as seen when we apply LSR to the Lynx model for Halueval. Similar results have been observed in the literature. [9] looks at the interaction between fine tuning and latent space approaches for steering model outputs. For most model behaviors studied, steering had an additional effect on top of the fine tuned model. However, they did observe a couple cases in which applying a latent space steering approach on top of model fine tuning counter-intuitively had less of an effect than just fine tuning alone. We see a similar result with the Lynx fine tuned model. This potentially points to an interesting research question of when fine tuning and latent space approaches work together and when they do not. In our own work with combining the two, we find a synergy, see “Beyond Detection: Numeric Scoring”.
LLM-as-Judge is an established approach to model-based evaluations in the literature and in practice, showing high correlation with human feedback for some evaluation tasks, e.g. comparisons [13].