
Hybrid Evaluation: Scaling human feedback with custom evaluation models
...how to really get model based evals to work for you



From talking with enterprises deploying LLM apps we’ve learned that incorporating human-in-the-loop feedback remains an important factor in evaluating LLM app output. In many situations, such as in customer support it’s still critical for a human agent to review the output of the LLM before it’s presented to the end user. This manual review becomes a limiting factor as it slows down the time before the LLM generated response can be shown to the end user. In addition, the manual review increases the cost of deploying an LLM app due to the human effort involved.
Model-based evaluation has been proposed as a cheaper and faster alternative to human feedback but has limitations due to bias and accuracy. Here, we share details about a hybrid evaluation system we built that combines the best of human and model-based approaches to build a robust and efficient evaluation system that overcomes some of these limitations. We build custom evaluation models via in-context learning (ICL, or few-shot-learning) and fine-tuning LLMs that are trained using human feedback data. On a 7-point summary grading task, we find that we can reduce the absolute error by 0.64 points (44%) through a combination of fine-tuning and building models at the individual human labeler level, as compared to using ICL only or building models aggregated across human labelers. The evaluation model also learns to generate an explanation for its grades. Finally, we demonstrate that we can fine-tune such models with as few as 25-50 human-labeled examples via a novel synthetic bootstrapping procedure inspired by the self-instruct paradigm to approach the accuracy of models trained on as many as 1000 real examples.

Dataset
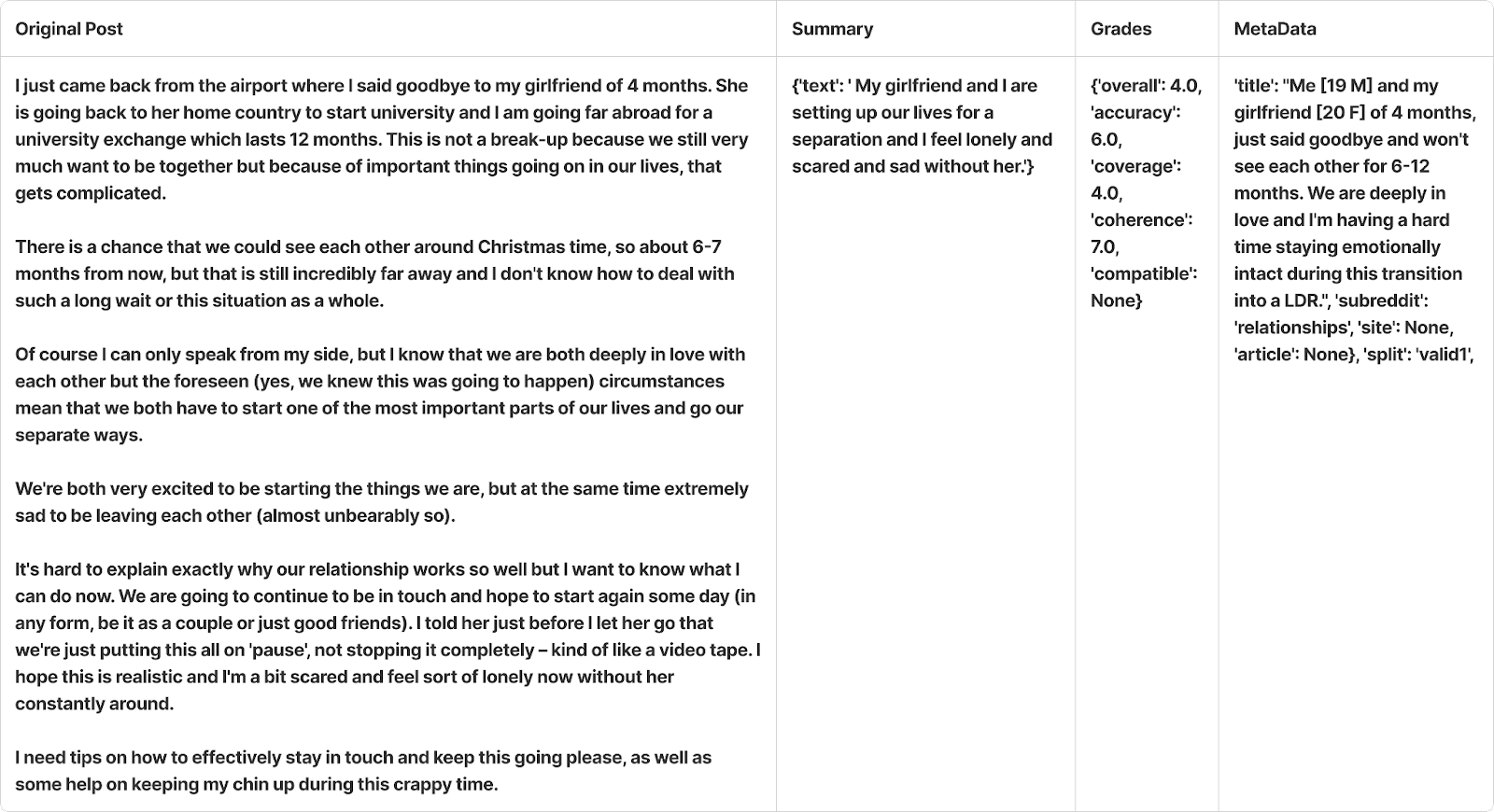
We used the Learning to Summarize from Human Feedback TL;DR dataset from OpenAI. In this dataset, human reviewers assigned grades on a scale of 1-7 to model and human-generated summaries of Reddit reviews. Summaries were graded across criteria such as coherence, accuracy, and coverage, as well as an overall score. In addition, a note provided a qualitative description of the reviewer’s reasoning behind the scores.
For the aggregate experiments, we used a subset of 5521 examples for the training set (either to draw ICL examples from or to use for fine-tuning), and a separate subset of 100 examples as the test set. For the worker level experiments, we chose the worker_id with the most examples (n=1424), and used varying subsets (n=5, 10, 25, or 50 with bootstrapping; or 1000) for training, and a separate subset of 100 examples for testing.
Here’s a sample prediction made by the model —

In real-world scenarios, organizations often face a problem with not having enough labelled examples to build an evaluation model. To address this issue, we developed a bootstrapping pipeline (inspired by self-instruct) with the following steps:
Generates synthetic, but statistically probable variations of the grades
The self-instruct style prompt instructs the model to understand the reviewer’s grading and note-generation process, and encourages diversity in the generated synthetic data
Several experiments were run with different iterations of the self-instruct prompt. A blind human (!) evaluation was performed to select the best-performing one.
In post-processing, semantically similar generations with a vector similarity > 0.85 were considered duplicates and one of the pairs was removed from the final dataset
Here’s a sample of synthetically generated data —

Through a human inspection process, we found that Claude-2 generated better synthetic data as compared to GPT-4. On average, it costs $0.019 to generate an accepted synthetic example, versus $0.66 per example for human annotations (assuming 2 min/example and $20/hr rate) resulting in a 35x cost savings.
Task
The aim for the hybrid evaluation models was to assign grades to the test example summary by mimicking the process by which grades were assigned to the summaries in the ICL or fine-tuning data examples.
We ran experiments that compared the following dimensions of the hybrid evaluation models:
Models trained on Worker (i.e., individual human reviewer) specific examples vs. models that aggregated examples across workers
Effect of number of ICL examples included in the prompt
Effect of the base model used: GPT4 vs. Claude-2 vs. GPT-3.5-turbo
Effect of fine-tuning the model
Comparison of models trained on real human reviewer data vs. models trained on bootstrapped synthetic data from a much smaller set of real data. We fine-tuned hybrid evaluation models using the synthetic data.
Results
Our key results were —
Worker (i.e., individual human reviewer) specific > Aggregate: We found ~8-10% reduction in absolute error when going from aggregate level to worker specific ICL for GPT4 and GPT-3.5.

For ICL, we found the performance to saturate at around 5 examples. The effect persisted even with longer context length models such as Claude-2.

Perhaps, not surprisingly: GPT4 > Claude-2 > GPT-3.5 (abs errors were 1.2, 1.33, and 1.45 respectively)
Fine tune > ICL - Fine tuning improved accuracy over ICL by 32% (Abs error: 1.45 -> 0.99) on aggregate and by 39% (Abs error: 1.32 -> 0.81) on worker level
With bootstrapping from 50 seed examples to 600 synthetic examples we can get within 0.045 points (6%) of the absolute error of as if having had 1000 labeled examples
The results are summarized below —

Digging further into the results comparing with and without self-instruct, we found that we could reduce the absolute error by 0.195 through the use of bootstrapping + fine-tuning.


System architecture for Log10’s hybrid evaluation system
Below we describe the architecture of Log10’s hybrid evaluation system and how it integrates with customers’ applications. Feedback on the LLM app output can be collected via in-app feedback or from in-house experts. This feedback is used to fine-tune a separate LLM that learns to mimic the human feedback. Optionally the collected data and feedback may be used towards fine-tuning a self-hosted model once enough data has been collected.
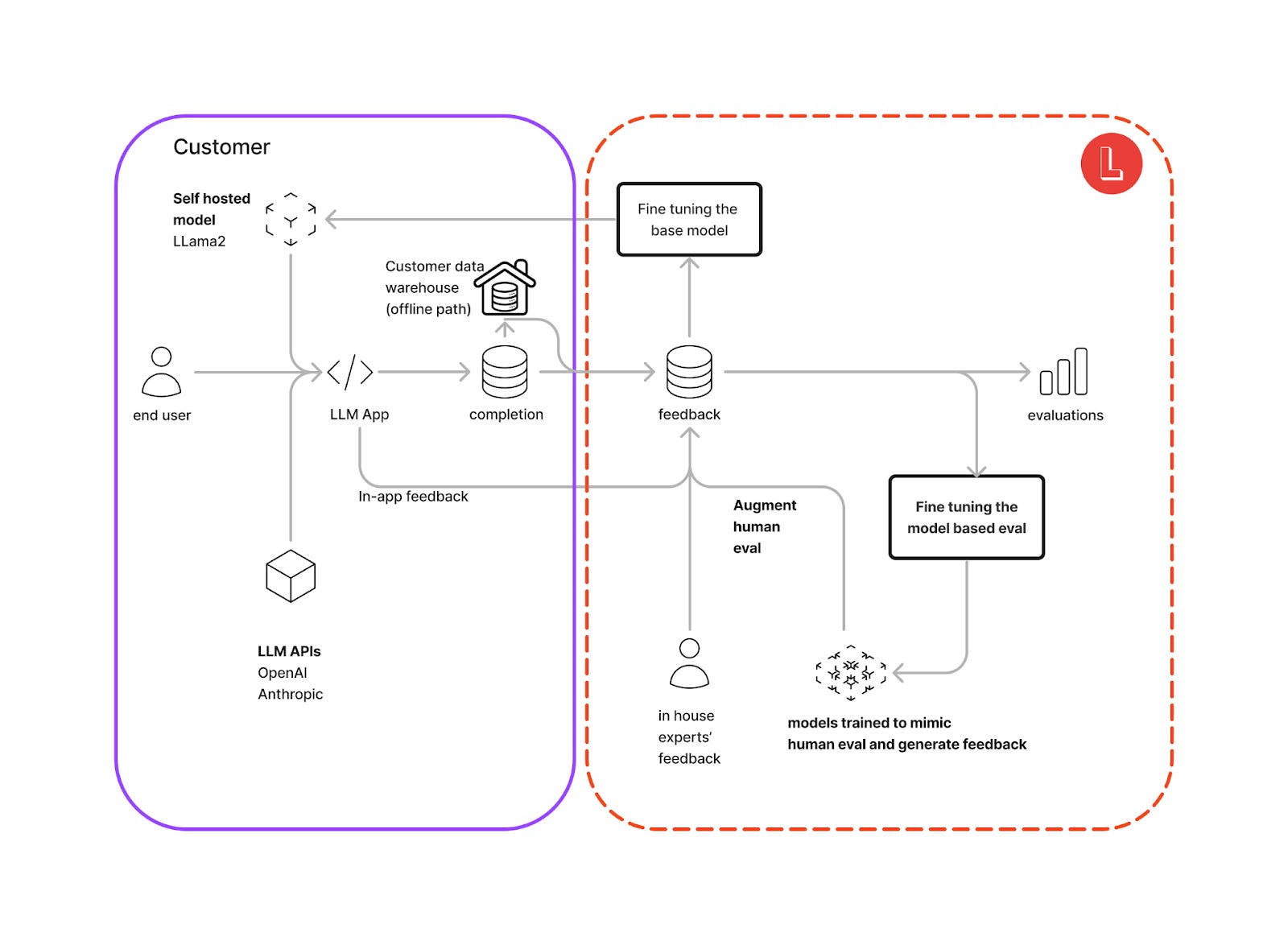
Once the model based feedback performs at the desired accuracy level, the need for human evaluators can be significantly reduced or eliminated, speeding up the LLM output response time back to end users and saving costs associated with manual review (see below).

Future directions
Fine-tuning open-source LLMs and comparing to the above results. This is especially important in situations where users need to self-host the evaluation model.
Extending the self-instruct bootstrap algorithm to use cases beyond summarization, and automating the self-instruct prompt creation
For enterprise LLM applications, depending on the use case, availability of labelled examples and the desired accuracy of the hybrid evaluation system one can calibrate the LLM used, and whether fine-tuning and bootstrapping are needed.
If you’ve been running into bottlenecks scaling your LLM applications due to the need for human feedback, do reach out to us at ai@log10.io. We’d love to hear from you!